绯冬荥韵 芳崋灼灼
冬
绯冬荥韵 芳崋灼灼
仅适用基于Hierarchical Softmax。
edit. 适用Negative Smapling
word2vec通过训练将每个词映射成K维实数向量。通过词之间的距离,比如cosine相似度,欧式距离等来判断他们之间的语义相似度。根据词频使用哈弗慢编码,使得所有词频相似的词隐藏层的激活内容基本一致。出现频率越高的词语,他们激活的隐藏层数目越少,这样有效的降低了计算的复杂度。
这篇文章是对TensorFlow官方例子:CIFAR-10数据集分类的理解记录。
对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别:
飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。
这里主要介绍cifar10_input.py、caifar10.py、caifar_train.py和cifar10_eval.py
训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择。Dropout是hintion最近2年提出的,源于其文章Improving neural networks by preventing co-adaptation of feature detectors.中文大意为:通过阻止特征检测器的共同作用来提高神经网络的性能。本篇博文就是按照这篇论文简单介绍下Dropout的思想。
大部分内容来源tornadomeet,先记录,之后填充。
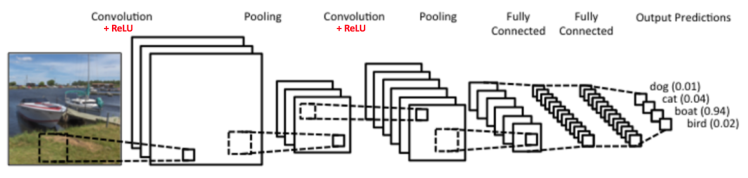
卷积神经网络-翻译 英文原文(ConvNets 或者 CNNs)属于神经网络的范畴,已经在诸如图像识别和分类的领域证明了其高效的能力。卷积神经网络可以成功识别人脸、物体和交通信号,从而为机器人和自动驾驶汽车提供视力。
当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计
首先给出对数形式的ERM的公式:
$$\min \frac{1}{n}\sum\limits_{i=1}^n L(y_i,p(y_i\mid x_i))$$
其中$L(y_i,f(x_i))$是损失函数,输出预测值为$f(x_i)$,n是观察到的样本数。
最大似然的前提是从模型总体随机抽取样本观测值,所有的采样都是独立同分布的。