先述
卷积神经网络-翻译 英文原文(ConvNets 或者 CNNs)属于神经网络的范畴,已经在诸如图像识别和分类的领域证明了其高效的能力。卷积神经网络可以成功识别人脸、物体和交通信号,从而为机器人和自动驾驶汽车提供视力。
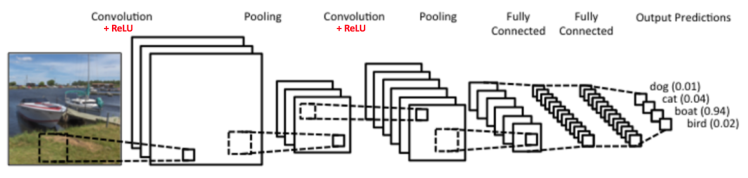
- 卷积
- 非线性处理(ReLU)
- 池化pooling
- 分类
图像是像素值的矩阵
本质上来说,每张图像都可以表示为像素值的矩阵:
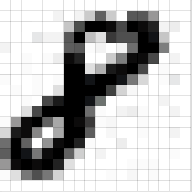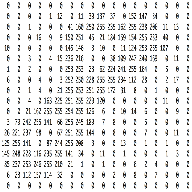
通道 (chain)常用于表示图像的某种组成。一个标准数字相机拍摄的图像会有三通道 - 红、绿和蓝;你可以把它们看作是互相堆叠在一起的二维矩阵(每一个通道代表一个颜色),每个通道的像素值在 0 到 255 的范围内。
灰度图像,仅仅只有一个通道。在本篇文章中,我们仅考虑灰度图像,这样我们就只有一个二维的矩阵来表示图像。矩阵中各个像素的值在 0 到 255 的范围内——零表示黑色,255 表示白色。
卷积
卷积的主要目的是为了从输入图像中提取特征。卷积可以通过从输入的一小块数据中学到图像的特征,并可以保留像素间的空间关系。
每张图像都可以看作是像素值的矩阵。考虑一下一个 5 x 5 的图像,它的像素值仅为 0 或者 1(注意对于灰度图像而言,像素值的范围是 0 到 255,下面像素值为 0 和 1 的绿色矩阵仅为特例),同时,考虑下另一个 3 x 3 的矩阵。接下来,5 x 5 的图像和 3 x 3 的矩阵的卷积可以按下图所示的动画一样计算:
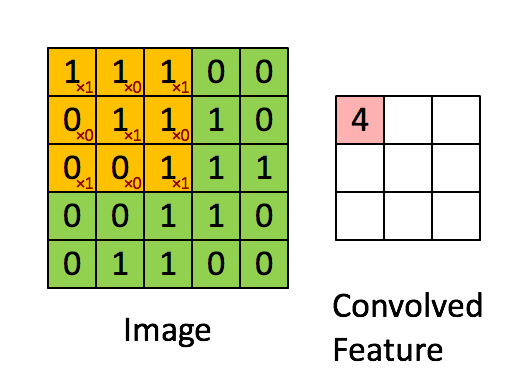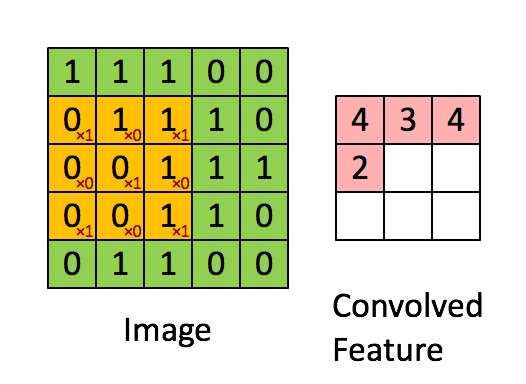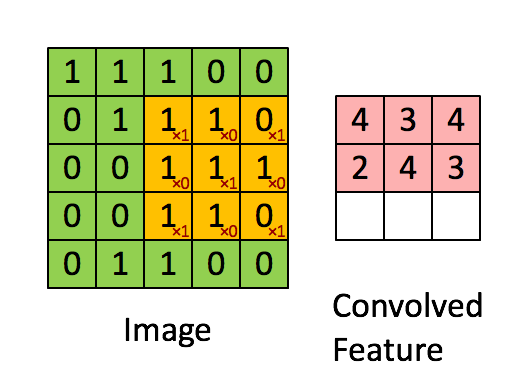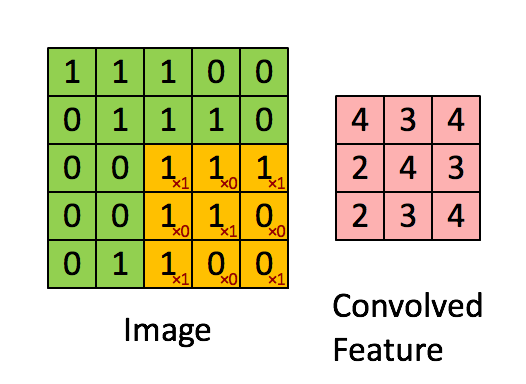
现在停下来好好理解下上面的计算是怎么完成的。我们用橙色的矩阵在原始图像(绿色)上滑动,每次滑动一个像素(也叫做“步长”),在每个位置上,我们计算对应元素的乘积(两个矩阵间),并把乘积的和作为最后的结果,得到输出矩阵(粉色)中的每一个元素的值。注意,3 x 3 的矩阵每次步长中仅可以“看到”输入图像的一部分。
在 CNN 的术语中,3x3 的矩阵叫做“滤波器(filter)”或者“核(kernel)”或者“特征检测器(feature detector)”,通过在图像上滑动滤波器并计算点乘得到矩阵叫做“卷积特征(Convolved Feature)”或者“激活图(Activation Map)”或者“特征图(Feature Map)”。记住滤波器在原始输入图像上的作用是特征检测器。
不同滤波器对上图卷积的效果。通过在卷积操作前修改滤波矩阵的数值,我们可以进行诸如边缘检测、锐化和模糊等操作 —— 这表明不同的滤波器可以从图中检测到不同的特征,比如边缘、曲线等。
在实践中,CNN 会在训练过程中学习到这些滤波器的值(尽管我们依然需要在训练前指定诸如滤波器的个数、滤波器的大小、网络架构等参数)。我们使用的滤波器越多,提取到的图像特征就越多,网络所能在未知图像上识别的模式也就越好。
特征图的大小(卷积特征)由下面三个参数控制,我们需要在卷积前确定它们:
深度(Depth):深度对应的是卷积操作所需的滤波器个数。在下图的网络中,我们使用三个不同的滤波器对原始图像进行卷积操作,这样就可以生成三个不同的特征图。你可以把这三个特征图看作是堆叠的 2d 矩阵,那么,特征图的“深度”就是三。
步长(Stride):步长是我们在输入矩阵上滑动滤波矩阵的像素数。当步长为 1 时,我们每次移动滤波器一个像素的位置。当步长为 2 时,我们每次移动滤波器会跳过 2 个像素。步长越大,将会得到更小的特征图。
零填充(Zero-padding):有时,在输入矩阵的边缘使用零值进行填充,这样我们就可以对输入图像矩阵的边缘进行滤波。零填充的一大好处是可以让我们控制特征图的大小。使用零填充的也叫做泛卷积,不适用零填充的叫做严格卷积。这个概念在下面的参考文献 14 中介绍的非常详细。
ReLU
每次的卷积操作后都使用了一个叫做 ReLU 的操作。ReLU 表示修正线性单元(Rectified Linear Unit),是一个非线性操作。它的输入如下所示:
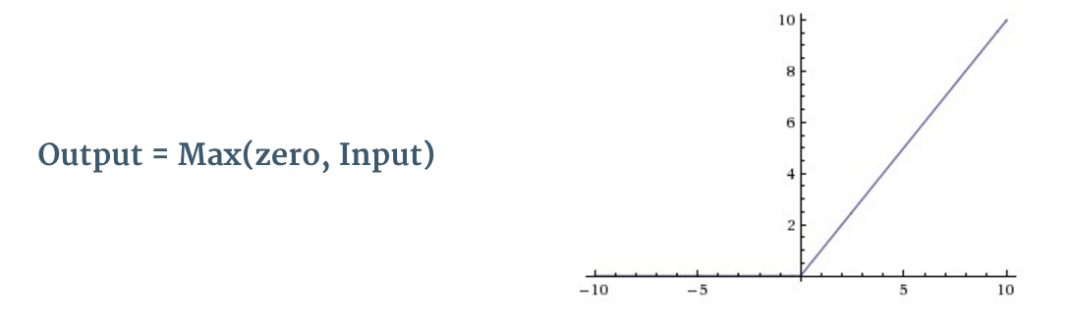
ReLU 是一个元素级别的操作(应用到各个像素),并将特征图中的所有小于 0 的像素值设置为零。ReLU 的目的是在 ConvNet 中引入非线性,因为在大部分的我们希望 ConvNet 学习的实际数据是非线性的(卷积是一个线性操作——元素级别的矩阵相乘和相加,所以我们需要通过使用非线性函数 ReLU 来引入非线性。
池化
空间池化(Spatial Pooling)(也叫做亚采用或者下采样)降低了各个特征图的维度,但可以保持大部分重要的信息。空间池化有下面几种方式:最大化、平均化、加和等等。
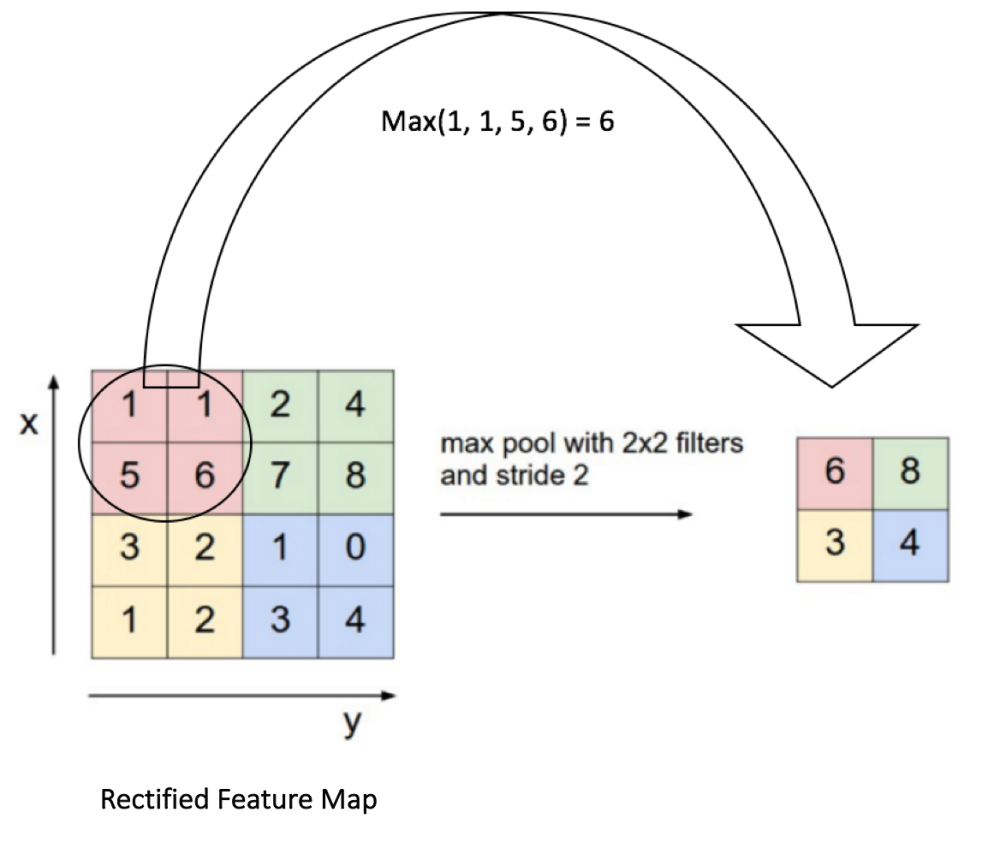
对于最大池化(Max Pooling),我们定义一个空间邻域(比如,2x2 的窗口),并从窗口内的修正特征图中取出最大的元素。除了取最大元素,我们也可以取平均(Average Pooling)或者对窗口内的元素求和。在实际中,最大池化被证明效果更好一些。
我们以 2 个元素(也叫做“步长”)滑动我们 2x2 的窗口,并在每个区域内取最大值。如上图所示,这样操作可以降低我们特征图的维度。
池化函数可以逐渐降低输入表示的空间尺度。特别地,池化:
- 使输入表示(特征维度)变得更小,并且网络中的参数和计算的数量更加可控的减小,因此,可以控制过拟合
- 使网络对于输入图像中更小的变化、冗余和变换变得不变性(输入的微小冗余将不会改变池化的输出——因为我们在局部邻域中使用了最大化/平均值的操作。
- 帮助我们获取图像最大程度上的尺度不变性(准确的词是“不变性”)。它非常的强大,因为我们可以检测图像中的物体,无论它们位置在哪里(参考 18 和 19 获取详细信息)。
到目前为止我们了解了卷积、ReLU 和池化是如何操作的。理解这些层是构建任意 CNN 的基础是很重要的。我们有两组卷积、ReLU & 池化层 —— 第二组卷积层使用六个滤波器对第一组的池化层的输出继续卷积,得到一共六个特征图。接下来对所有六个特征图应用 ReLU。接着我们对六个修正特征图分别进行最大池化操作。
这些层一起就可以从图像中提取有用的特征,并在网络中引入非线性,减少特征维度,同时保持这些特征具有某种程度上的尺度变化不变性。
第二组池化层的输出作为全连接层的输入,我们会在下一部分介绍全连接层。
全连接层
全连接层是传统的多层感知器,在输出层使用的是 softmax 激活函数(也可以使用其他像 SVM 的分类器,但在本文中只使用 softmax)。“全连接(Fully Connected)”这个词表明前面层的所有神经元都与下一层的所有神经元连接。
卷积和池化层的输出表示了输入图像的高级特征。全连接层的目的是为了使用这些特征把输入图像基于训练数据集进行分类。
除了分类,添加一个全连接层也(一般)是学习这些特征的非线性组合的简单方法。从卷积和池化层得到的大多数特征可能对分类任务有效,但这些特征的组合可能会更好。
从全连接层得到的输出概率和为 1。这个可以在输出层使用 softmax 作为激活函数进行保证。softmax 函数输入一个任意大于 0 值的矢量,并把它们转换为零一之间的数值矢量,其和为一。
卷积 + 池化层的作用是从输入图像中提取特征,而全连接层的作用是分类器。
小结
完整的卷积网络的训练过程可以总结如下:
第一步:我们初始化所有的滤波器,使用随机值设置参数/权重
第二步:网络接收一张训练图像作为输入,通过前向传播过程(卷积、ReLU 和池化操作,以及全连接层的前向传播),找到各个类的输出概率
- 我们假设船这张图像的输出概率是 [0.2, 0.4, 0.1, 0.3]
- 因为对于第一张训练样本的权重是随机分配的,输出的概率也是随机的
- 第三步:在输出层计算总误差(计算 4 类的和)
- Total Error = ∑ ½ (target probability – output probability) ²
- 第四步:使用反向传播算法,根据网络的权重计算误差的梯度,并使用梯度下降算法更新所有滤波器的值/权重以及参数的值,使输出误差最小化
- 权重的更新与它们对总误差的占比有关
- 当同样的图像再次作为输入,这时的输出概率可能会是 [0.1, 0.1, 0.7, 0.1],这就与目标矢量 [0, 0, 1, 0] 更接近了
- 这表明网络已经通过调节权重/滤波器,可以正确对这张特定图像的分类,这样输出的误差就减小了
- 像滤波器数量、滤波器大小、网络结构等这样的参数,在第一步前都是固定的,在训练过程中保持不变——仅仅是滤波器矩阵的值和连接权重在更新
- 第五步:对训练数据中所有的图像重复步骤 1 ~ 4
补充
有时候,我们会在池化前后进行局部对比度归一化层(local contract normalization)。这个归一化包括两个部分:局部做减和局部做除
自然图像存在低阶和高阶的统计特征,低阶(例如二阶)的统计特征是满足高斯分布的,但高阶的统计特性是非高斯分布。图像中,空间上相邻的像素点有着很强的相关性。而对于PCA来说,因为它是对协方差矩阵操作,所以可以去掉输入图像的二阶相关性,但是却无法去掉高阶相关性。而有人证明了除以一个隐含的变量就可以去除高阶相关性。
对输入图像的每一个像素,我们计算其邻域(例如3x3窗口)的均值,然后每个像素先减去这个均值,再除以这个邻域窗口(例如3x3窗口)拉成的9维向量的欧几里德范数(如果这个范数大于1的时候才除:这个约束是为了保证归一化只作用于减少响应(除以大于1的数值变小),而不会加强响应(除以小于1的数值变大))。也有论文在计算均值和范数的时候,都加入了距离的影响,也就是距离离该窗口中心越远,影响越小,例如加个高斯权重窗口(空间上相邻的像素点的相关性随着距离变大而变小)。
数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如(0.1,0.9) 。
为什么要归一化处理?
- 输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
- 数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
- 由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
- S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。
