神经元
Neural Network神经网络:是由具有适应性的简单单元组成的广泛并进行互联的网络,他的组织能够模拟生物神经系统对真实的世界物体做出的交互反应
神经网络由一个个神经元(neuron)互联组成,神经元可以看作一个处理函数,当这个函数的输入超过某一个阈值,经过处理后单元会向其他单元发送信号。
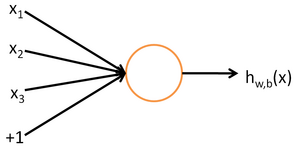
单元的输入来自其他单元传递过来的信号,这些信号通过带权重的连接进行传递。当前单元接受来自其余单元的带权重的信号和与阈值比较,符合条件的产生输出。
感知机
感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是阈值逻辑单元。
感知机通过简单的算术组合可以轻易的实现与或非逻辑运算。
实现逻辑类似于$y=f(\sum_i\omega_ix_i-\theta)$,其中w是权重向量,x是输入信号,$\theta$则是阈值。
阈值可看作是一个固定输入(x值)为-1的dummy node所对应的连接权重$\omega_{n+1}$,这样权重和阈值就可以统一学习。
学习规则
$\omega_i \leftarrow \omega_i + \Delta \omega_i$
$\Delta \omega_i = \eta(y-\hat{y})x_i$
其中$\eta \in (0,1)$称为学习率。若感知机对训练样例(x,y)预测正确,即$\hat{y}=y$,则感知机不改变,否则将根据错误的程度进行权重调整。
非线性与多重神经元
要解决非线性可分问题,需考虑多层功能神经元。例如异或问题。
一般的多层功能神经元都设置在输入层与输出层之间,也称作隐含层。每一层都有独立的激活函数功能神经元。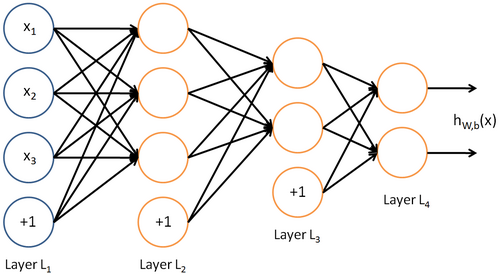
功能更强大的神经网络:每层神经元与下一层神经元完全互联,而同层之间不存在连接,也不存在跨层连接。要注意的是,这里的相邻层连接是双向的。这种分类型的神经网络通常被称为”多层前馈神经网络”(multi-layer feedforward neural networks)这种网络的输入层的功能仅仅是接受输入,隐层以及输出层有功能神经元,进行函数处理。
学习过程
神经网络就是根据训练数据来调整神经元之间的连接权以及每个功能神经元的阈值。
著名的BP算法就是神经网络一种训练学习算法。
BP误差逆传
多层神经网络中最著名的学习算法就是BP误差逆传算法(erroe BackPropagation)。
BP算法可以训练包括多层前馈神经网络、递归神经网络等。
BP算法的目标是要最小化训练集D上的累计误差。作为一个迭代类型的算法,,迭代的每一轮采用广义的感机学习规则对参数进行更新估计。其中学习率$\eta \in (0,1)$控制着算法中每次迭代的更新步长,$\eta$太大容易造成迭代的震荡,太小则会影响收敛速度,
算法流程
将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果
计算输出层的误差,将误差逆向传播至隐层神经元
根据隐层神经元的误差对连接券和阈值进行调整
迭代,直到达到某个停止条件,如训练误差小于某个数值
以目标的负梯度方向为参数进行调整。分别计算出输出层、隐层的梯度以及对应的阈值bias,然后去更新神经元之间的权值和阈值。再进行输出层隐层的梯度。。。不断的循环,直到误差小于预设值。
对过拟合的策略
由于BP算法强大的学习能力,经常会在训练集上过度学习造成过拟合现象,反而在测试集上的表现不好。通常可以采用”早停”策略:将数据集分为训练集和验证集,训练集用来计算梯度、更新连接权以及阈值,验证集则用来估计误差。训练集误差降低但验证集误差升高时,停止训练,同时返回具有最小验证集误差的连接权和阈值。
全局与局部
用E表示神经网络在训练集上的误差,则E是关于连接权w和阈值$\theta$的函数,此时神经网络的训练过程可看作是一个参数的寻优过程,即在参数空间中找一组最优参数使得E最小。
直观的得看,局部最小解(local minimum)是参数空间中的某个点,它相邻的误差函数值均不小于该点的函数值;
全局最小解(global minimum)是指参数空间中所有的点误差函数值都不小于该店的误差函数值。
显然有全局最小解必然是局部最小解,反之未必。参数空间中梯度为零的点,其误差值小于临点的误差函数值,称为局部最小。
搜索方式
根据梯度的值决定参数最优搜索的方向是最广泛的办法。例如负梯度方向是函数值下降最快的方向,因此梯度下降法就是沿着负梯度方向搜索最优解。若误差函数在当前点的梯度为零,则已达到局部极小。
如果只有一个局部最小点,则为全局最小解。从局部最优找到全局最优的办法就是要从局部最优中挑出来,继续搜索下去。因为搜索到局部最优后,梯度为零,会造成搜索停滞。
取多组不同参数值初始化多个神经网络,取其中误差最小的解作为最终的参数。相当于从不同的初始值开始搜索猜测。
使用模拟退火法(在blog之前的文章中有介绍)。模拟退退火有一定的概率接受比当前解差的解,有助于跳出局部极小。而迭代过程,接受次优解的概率逐渐降低,从而保证了算法的稳定性。
随机梯度下降
其余常见的神经网络
RBF网络
单隐层前馈神经网络的一种,输出层是对隐层神经元还输出的线性组合。假定输入为d维向量$\vec{x}$输出为实值,可表示为:
$\phi(x)=\sum_{i=1}^{q}\omega_i\rho(x,c_i)$
q为隐层神经元个数,$c_i$和$\omega_i$分别是第i个隐层神经元对应的中心和权重。$\rho(x,c_i)$是径向基函数,是某种沿径向对称的标量函数。通常定义为样本x到数据中心
$c_i$之间的欧式距离的单调函数。
ART网络
竞争学习(competitive learning)是神经网络中常用的无监督学习策略。
网络的输出神经元相互竞争,每一时刻仅有一个竞争获胜的神经元被激活,其他神经元状态被抑制。
SOM网络
自组织映射,是一种竞争学习型的无监督神经网络。能将高位输入数据降维,同时保持输入数据的拓扑结构。即将高维空间中相似的样本点映射到网络输出层的邻近神经元。
在接受一个训练样本之后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元称为最佳匹配单元。然后调整最佳匹配单元及邻近神经元的权向量,使得这些权向量与当前输入样本距离缩小。这个过程不断迭代,知道收敛。
级连相关
级联: 建立层次连接的层级结构。开始训练时,只有几本的输入输出层,随着训练的进行,新的隐层神经元逐渐加入。
相关: 通过最大化新神经元的输出与网络误差之间的相关性来训练相关的参数。
Elman
Elman网络是递归神经网络(recurrent neural networks)的一种。递归神经网络可以让一些神经元的输出反馈作为输入信号。
深度学习
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分.不同的学习框架下建立的学习模型很是不同.例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。
DBN每次训练一层隐节点,训练时将上一层隐节点的输出作为下一层隐节点的输入。整个网络完成后,再进程微调。
CNN节省训练开销的策略是”权共享”,让一组神经元使用相同的连接权。
无论是DBN还是CNN,其多隐层堆叠,每层对上层的处理机制,可以看作是对输入信号逐层加工,从而把初始的与输出目标联系不密切的输入转换呈密切。通过多层处理,逐渐的将初始的低层特征转转成高层特征表示,用简单模型完成复杂的分类任务。
CNN卷积神经网络
在图像处理中,往往把图像表示为像素的向量,比如一个1000×1000的图像,可以表示为一个1000000的向量。在上一节中提到的神经网络中,如果隐含层数目与输入层一样,即也是1000000时,那么输入层到隐含层的参数数据为1000000×1000000=10^12,这样就太多了,基本没法训练。所以图像处理要想练成神经网络大法,必先减少参数加快速度。
卷积神经网络有两种神器可以降低参数数目。第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
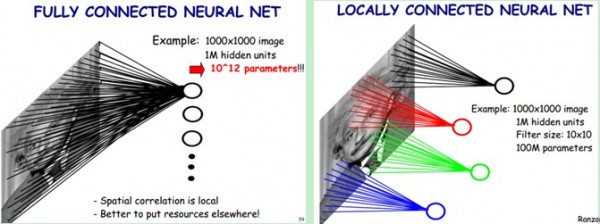
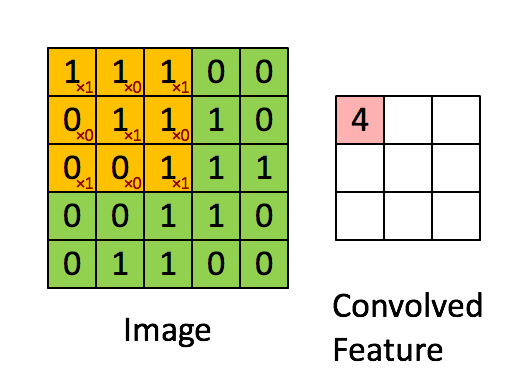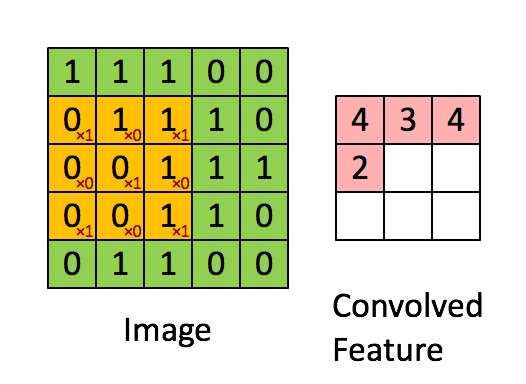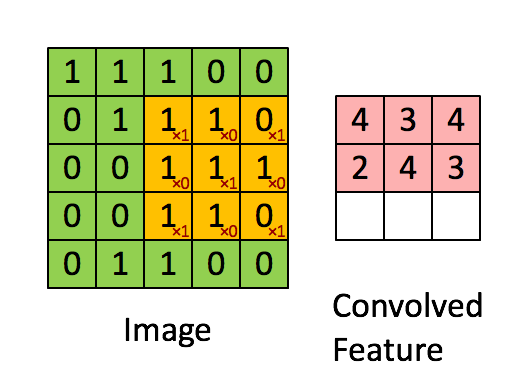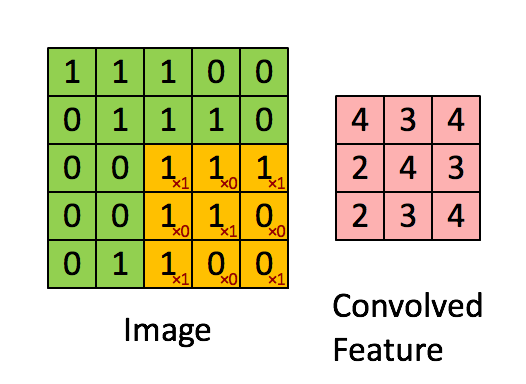
在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8×8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8×8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8×8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。