示例有d个属性$(x_1 ; x_2 ; x_3… ; x_d)$描述,线性模型试图学得一个通过属性的线性组合来进行预测的函数。
$f(x)=w_1x_1+w_2x_2+…+w_dx_d+b$,w和b确定后,模型就确定了。w直观表达了各属性在预测中的重要性。
线性回归
线性回归试图学得$f(x_i)=wx_i+b$,使得$f(x_i) \approx y_i$
确定w和b的关键是衡量f(x)与y之间的关系。我们可以通过使用均方误差最小化作为衡量标准。
对数几率回归
对数几率回归实际上针对的是分类任务,将分类任务的真实标记y和回归模型的预测值联系起来。
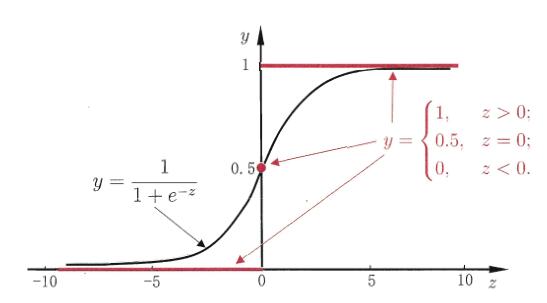
分类任务,通过类阶跃函数(阶跃函数不连续),把连续的值近似的分成两类(0或1),并且在坐标原点处变得很陡。
线性判别分析
Linear Discriminant Analysis是一种经典的线性学习方法:给定训练样例集,设法将样例投射到一条直线上,1. 使得同样样例的投影点尽可能的接近,2. 异类样例投射点尽可能远。对测试集预测时,将对象投射到直线上预测。
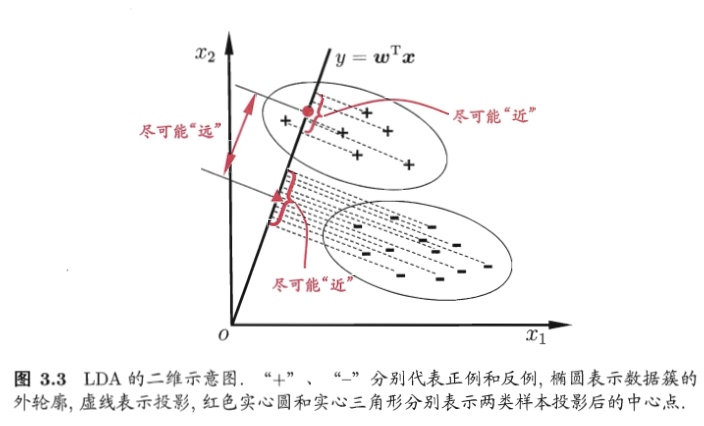
要实现上面的两个目标,分别考虑:对于同类样本投射点接近,计算同类样本点的均值方差A;异类点则考虑两个样本簇中心点的距离差最大|xa-xb|²,然后使用单一的数值,J=A/B,使J尽可能的大。
多分类策略
这里简单介绍通过二分策略实现多分类策略,常用的有三种方法,核心是拆解的策略区别:
一对一(OvO):任意两个对象亮亮配对,产生N*(N-1)/2个预测结果,在这些结果中投票,预测结果最多的视为最终结果
一对多(OvR):每次从训练集中挑选一个不重复的样例作为正例,其余N-1个样例作为反例,进行N次训练。如果某次训练的结果预测为正类,此次训练的样例即为结果;若有多个样例被预测为正例,考虑事先设置的置信度,选择置信度最大的
多对多(MvM):每次将若干类作为正类,若干类作为反类。这里提供一种常用的MvM拆分模式,就错输出吗ECOC。ECOC进行M次的划分,也就是M次分类器。分别对测试样本进行预测,这些预测标记组成一个编码,然后编码与每个类别各自的编码进行比较,返回其中距离和最小的作为最终预测结果。
