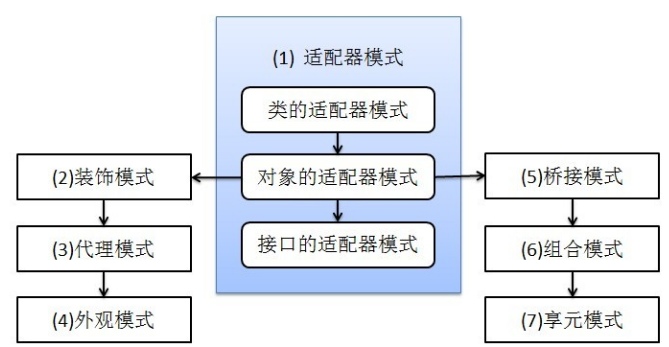
上图表示的就是本文介绍的几种设计模式之间关系,其中对象的适配器模式是基础。
我们一个个讲,先看类的适配器模式:

类的适配器模式
核心思想就是:有一个Source类,拥有一个方法,待适配,目标接口是Targetable,通过Adapter类,将Source的功能扩展到Targetable里:
1 | //Source类 |
这样Targetable接口的实现类就具有了Source类的功能。
对象的适配器模式
对象的适配器模式基本思路和类的适配器模式相同,只是将Adapter类作修改,这次不继承Source类,而是持有Source类的实例,以达到解决兼容性的问题。

1 | public class Wrapper implements Targetable { |
接口的适配器模式
有时我们写的一个接口中有多个抽象方法,当我们写该接口的实现类时,必须实现该接口的所有方法,这明显有时比较浪费,因为并不是所有的方法都是我们需要的,有时只需要某一些,此处为了解决这个问题,我们引入了接口的适配器模式,借助于一个抽象类,该抽象类实现了该接口,实现了所有的方法,而我们不和原始的接口打交道,只和该抽象类取得联系,所以我们写一个类,继承该抽象类,重写我们需要的方法就行。

1 | public interface Targetable { |
三种适配器的区别
类的适配器模式:当希望将一个类转换成满足另一个新接口的类时,可以使用类的适配器模式,创建一个新类,继承原有的类,实现新的接口即可。
对象的适配器模式:当希望将一个对象转换成满足另一个新接口的对象时,可以创建一个Wrapper类,持有原类的一个实例,在Wrapper类的方法中,调用实例的方法就行。
接口的适配器模式:当不希望实现一个接口中所有的方法时,可以创建一个抽象类Wrapper,实现所有方法,我们写别的类的时候,继承抽象类即可。
装饰模式
装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例

Source类是被装饰类,Decorator类是一个装饰类,可以为Source类动态的添加一些功能
1 | public interface Sourceable { |
装饰模式可以动态的为一个对象增加功能,而且还能动态撤销。继承是无法做到这一点的,只能是静态的增加。
代理模式
代理模式就是多一个代理类出来,替原对象进行一些操作,比如我们在租房子的时候回去找中介,为什么呢?因为你对该地区房屋的信息掌握的不够全面,希望找一个更熟悉的人去帮你做,此处的代理就是这个意思。再如我们有的时候打官司,我们需要请律师,因为律师在法律方面有专长,可以替我们进行操作,表达我们的想法。先来看看关系图:

1 | public interface Sourceable { |
适用范围
当我们想要把已有的方法在使用的时候对原有的方法进行改进,有2种思路:
修改原有的方法来适应。这样违反了“对扩展开放,对修改关闭”的原则。
采用一个代理类调用原有的方法,且对产生的结果进行控制。这种方法就是代理模式。
使用代理模式,可以将功能划分的更加清晰,有助于后期维护!
外观模式
外观模式是为了解决类与类之家的依赖关系的,可以将类和类之间的关系配置到配置文件中,而外观模式就是将他们的关系放在一个Facade类中,降低了类类之间的耦合度,该模式中没有涉及到接口

1 | public class CPU { |
如果我们没有Computer类,那么,CPU、Memory、Disk他们之间将会相互持有实例,产生关系,这样会造成严重的依赖,修改一个类,可能会带来其他类的修改,这不是我们想要看到的,有了Computer类,他们之间的关系被放在了Computer类里,这样就起到了解耦的作用
桥接模式
桥接模式就是把事物和其具体实现分开,使他们可以各自独立的变化。桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化,像我们常用的JDBC桥DriverManager一样,JDBC进行连接数据库的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不用动,原因就是JDBC提供统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了

1 | public interface Sourceable { |
这里我们顺带的将JDBC的模式图展示出来:

组合模式
组合模式有时又叫部分-整体模式在处理类似树形结构的问题时比较方便

1 | public class TreeNode { |
使用场景:将多个对象组合在一起进行操作,常用于表示树形结构中,例如二叉树,数等。
享元模式
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。

FlyWeightFactory负责创建和管理享元单元,当一个客户端请求时,工厂需要检查当前对象池中是否有符合条件的对象,如果有,就返回已经存在的对象,如果没有,则创建一个新对象,FlyWeight是超类。一提到共享池,我们很容易联想到Java里面的JDBC连接池,想想每个连接的特点,我们不难总结出:适用于作共享的一些个对象,他们有一些共有的属性,就拿数据库连接池来说,url、driverClassName、username、password及dbname,这些属性对于每个连接来说都是一样的,所以就适合用享元模式来处理,建一个工厂类,将上述类似属性作为内部数据,其它的作为外部数据,在方法调用时,当做参数传进来,这样就节省了空间,减少了实例的数量。
看个例子:

看下数据库连接池的代码:
1 | public class ConnectionPool { |
通过连接池的管理,实现了数据库连接的共享,不需要每一次都重新创建连接,节省了数据库重新创建的开销,提升了系统的性能.
