文章摘录自周志华老师《机器学习与数据挖掘》.
机器学习是人工智能的核心研究领域之一, 其最初的研究动机是为了让计算机系统具有人的学习能力以便实现人工智能,因为众所周知,没有学习能力的系统很难被认为是具有智能的。目前被广泛采用的机器学习的定义是“利用经验来改善计算机系统自身的性能”。事实上,由于“经验”在计算机系统中主要是以数据的形式存在的,因此机器学习需要设法对数据进行分析,这就使得它逐渐成为智能数据分析技术的创新源之一,并且为此而受到越来越多的关注。
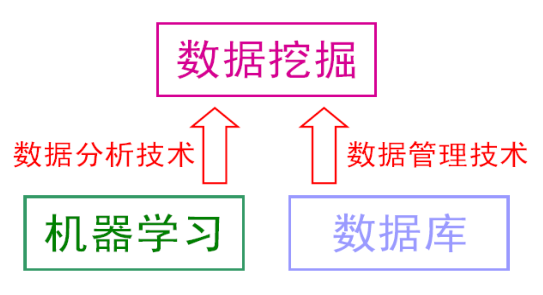
“数据挖掘”和“知识发现”通常被相提并论,并在许多场合被认为是可以相互替代的术语。对数据挖掘有多种文字不同但含义接近的定义,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程”。其实顾名思义,数据挖掘就是试图从海量数据中找出有用的知识。大体上看数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。因为机器学习和数据挖掘有密切的联系,受主编之邀,本文把它们放在一起做一个粗浅的介绍。
1980 年夏天,在美国卡内基梅隆大学举行了第一届机器学习研讨会;同年,《策略分析与信息系统》连出三期机器学习专辑;1983 年,Tioga出版社出版了R.S. Michalski、J.G. Carbonell和T.M.Mitchell主编的《机器学习:一种人工智能途径》,书中汇集了 20 位学者撰写的 16 篇文章,对当时的机器学习研究工作进行了总结,产生了很大反响;1986 年,《Machine Learning》创刊;1989 年,《Artificial Intelligence》出版了机器学习专辑,刊发了一些当时比较活跃的研究工作,其内容后来出现在J.G. Carbonell主编、MIT出版社 1990 年出版的《机器学习:风范与方法》一书中。总的来看,20 世纪 80 年代是机器学习成为一个独立的学科领域并开始快速发展、各种机器学习技术百花齐放的时期。
R.S. Michalski等人中把机器学习研究划分成“从例子中学习”、“在问题求解和规划中学习”、“通过观察和发现学习”、“从指令中学习”等范畴;而E.A. Feigenbaum在著名的《人工智能手册》中,则把机器学习技术划分为四大类,即“机械学习”、“示教学习”、“类比学习”、“归纳学习”。机械学习也称为“死记硬背式学习”,就是把外界输入的信息全部记下来,在需要的时候原封不动地取出来使用,这实际上没有进行真正的学习;示教学习和类比学习实际上类似于R.S. Michalski等人所说的“从指令中学习”和“通过观察和发现学习”;归纳学习类似于“从例子中学习”,即从训练例中归纳出学习结果 c 。20 世纪 80 年代以来,被研究得最多、应用最广的是“从例子中学习”(也就是广义的归纳学习),它涵盖了监督学习(例如分类、回归)、非监督学习(例如聚类)等众多内容。下面我们对这方面主流技术的演进做一个简单的回顾。
在 20 世纪 90 年代中期之前,“从例子中学习”的一大主流技术是归纳逻辑程序设计(Inductive Logic Programming),这实际上是机器学习和逻辑程序设计的交叉。它使用 1 阶逻辑来进行知识表示,通过修改和扩充逻辑表达式(例如Prolog表达式)来完成对数据的归纳。这一技术占据主流地位与整个人工智能领域的发展历程是分不开的。如前所述,人工智能在 20 世纪 50 年代到 80 年代经历了“推理期”和“知识期”,在“推理期”中人们基于逻辑知识表示、通过演绎技术获得了很多成果,而在知识期中人们基于逻辑知识表示、通过领域知识获取来实现专家系统,因此,逻辑知识表示很自然地受到青睐,而归纳逻辑程序设计技术也自然成为机器学习的一大主流。归纳逻辑程序设计技术的一大优点是它具有很强的知识表示能力,可以较容易地表示出复杂数据和复杂的数据关系。尤为重要的是,领域知识通常可以方便地写成逻辑表达式,因此,归纳逻辑程序设计技术不仅可以方便地利用领域知识指导学习,还可以通过学习对领域知识进行精化和增强,甚至可以从数据中学习出领域知识。事实上,机器学习在 20 世纪 80 年代正是被视为“解决知识工程瓶颈问题的关键”而走到人工智能主舞台的聚光灯下的,归纳逻辑程序设计的一些良好特性对此无疑居功至伟。
然而,归纳逻辑程序设计技术也有其局限,最严重的问题是由于其表示能力很强,学习过程所面临的假设空间太大,对规模稍大的问题就很难进行有效的学习,只能解决一些“玩具问题”。因此,在 90 年代中期后,归纳程序设计技术方面的研究相对陷入了低谷。
机器学习之所以备受瞩目,主要是因为它已成为智能数据分析技术的创新源之一。但是机器学习还有一个不可忽视的功能,就是通过建立一些关于学习的计算模型来帮助人们了解“人类如何学习”。
数据挖掘的对象早就不限于数据库,而可以是存放在任何地方的数据,甚至包括Internet上的数据。
数据挖掘受到了很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。粗糙地说,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学界往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。
从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域。但能否认为数据挖掘只不过就是机器学习的简单应用呢?答案是否定的。一个重要的区别是,传统的机器学习研究并不把海量数据作为处理对象,很多技术是为处理中小规模数据设计的,如果直接把这些技术用于海量数据,效果可能很差,甚至可能用不起来。因此,数据挖掘界必须对这些技术进行专门的、不简单的改造。例如,决策树是一种很好的机器学习技术,不仅有很强的泛化能力,而且学得结果具有一定的可理解性,很适合数据挖掘任务的需求。但传统的决策树算法需要把所有的数据都读到内存中,在面对海量数据时这显然是无法实现的。为了使决策树能够处理海量数据,数据挖掘界做了很多工作,例如通过引入高效的数据结构和数据调度策略等来改造决策树学习过程,而这其实正是在利用数据库界所擅长的数据管理技术。实际上,在传统机器学习算法的研究中,在很多问题上如果能找到多项式时间的算法可能就已经很好了,但在面对海量数据时,可能连O(n 3 )的算法都是难以接受的,这就给算法的设计带来了巨大的挑战。
为一个独立的学科领域,必然会有一些相对“独特”的东西。对数据挖掘来说,这就是关联分析。简单地说,关联分析就是希望从数据中找出“买尿布的人很可能会买啤酒”这样看起来匪夷所思但可能很有意义的模式。
实际上,在面对少量数据时关联分析并不难,可以直接使用统计学中有关相关性的知识,这也正是机器学习界没有研究关联分析的一个重要原因。关联分析的困难其实完全是由海量数据造成的,因为数据量的增加会直接造成挖掘效率的下降,当数据量增加到一定程度,问题的难度就会产生质变,例如,在关联分析中必须考虑因数据太大而无法承受多次扫描数据库的开销、可能产生在存储和计算上都无法接受的大量中间结果等,而关联分析技术正是围绕着“提高效率”这条主线发展起来的。
